Bootstrap
Import and settings
In this example, we need to import numpy, pandas, and graphviz in addition to lingam.
import numpy as np
import pandas as pd
import graphviz
import lingam
from lingam.utils import print_causal_directions, print_dagc, make_dot
import warnings
warnings.filterwarnings("ignore")
print([np.__version__, pd.__version__, graphviz.__version__, lingam.__version__])
np.set_printoptions(precision=3, suppress=True)
np.random.seed(0)
['1.26.4', '2.3.3', '0.21', '1.12.1']
Test data
We create test data consisting of 6 variables.
_size = 100
x3 = np.random.uniform(size=_size)
x0 = 3.0*x3 + np.random.uniform(size=_size)
x2 = 6.0*x3 + np.random.uniform(size=_size)
x1 = 3.0*x0 + 2.0*x2 + np.random.uniform(size=_size)
x5 = 4.0*x0 + np.random.uniform(size=_size)
x4 = 8.0*x0 - 1.0*x2 + np.random.uniform(size=_size)
X = pd.DataFrame(np.array([x0, x1, x2, x3, x4, x5]).T ,columns=['x0', 'x1', 'x2', 'x3', 'x4', 'x5'])
X.head()
| x0 | x1 | x2 | x3 | x4 | x5 | |
|---|---|---|---|---|---|---|
| 0 | 2.324257 | 15.088680 | 3.604677 | 0.548814 | 15.299760 | 9.698288 |
| 1 | 2.415576 | 17.995735 | 4.987480 | 0.715189 | 14.710164 | 10.591596 |
| 2 | 2.543484 | 15.952262 | 3.994332 | 0.602763 | 16.878512 | 10.273552 |
| 3 | 2.596838 | 14.769421 | 3.448903 | 0.544883 | 18.076397 | 11.332654 |
| 4 | 1.519718 | 10.099609 | 2.566608 | 0.423655 | 9.924640 | 6.948359 |
m = np.array([[0.0, 0.0, 0.0, 3.0, 0.0, 0.0],
[3.0, 0.0, 2.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 6.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[8.0, 0.0,-1.0, 0.0, 0.0, 0.0],
[4.0, 0.0, 0.0, 0.0, 0.0, 0.0]])
make_dot(m)

Bootstrapping
We call bootstrap() method instead of fit(). Here, the second argument specifies the number of bootstrap sampling.
n_samples = 1000
model = lingam.DirectLiNGAM()
result = model.bootstrap(X, n_sampling=n_samples)
Causal Directions
Since BootstrapResult object is returned, we can get the ranking of the causal directions extracted by get_causal_direction_counts() method. In the following sample code, n_directions option is limited to the causal directions of the top 8 rankings, and min_causal_effect option is limited to causal directions with a coefficient of 0.01 or more.
cdc = result.get_causal_direction_counts(n_directions=8, min_causal_effect=0.01, split_by_causal_effect_sign=True)
We can check the result by utility function.
print_causal_directions(cdc, n_samples)
x4 <--- x2 (b<0) (87.9%)
x4 <--- x0 (b>0) (86.6%)
x1 <--- x2 (b>0) (77.5%)
x1 <--- x0 (b>0) (77.3%)
x2 <--- x3 (b>0) (76.1%)
x5 <--- x0 (b>0) (75.4%)
x0 <--- x3 (b>0) (45.4%)
x0 <--- x5 (b>0) (24.6%)
Directed Acyclic Graphs
Also, using the get_directed_acyclic_graph_counts() method, we can
get the ranking of the DAGs extracted. In the following sample code,
n_dags option is limited to the dags of the top 3 rankings, and
min_causal_effect option is limited to causal directions with a
coefficient of 0.01 or more.
dagc = result.get_directed_acyclic_graph_counts(n_dags=3, min_causal_effect=0.01, split_by_causal_effect_sign=True)
We can check the result by utility function.
print_dagc(dagc, n_samples)
DAG[0]: 17.0%
x0 <--- x3 (b>0)
x1 <--- x0 (b>0)
x1 <--- x2 (b>0)
x2 <--- x3 (b>0)
x4 <--- x0 (b>0)
x4 <--- x2 (b<0)
x5 <--- x0 (b>0)
DAG[1]: 4.2%
x0 <--- x3 (b>0)
x1 <--- x0 (b>0)
x1 <--- x2 (b>0)
x3 <--- x2 (b>0)
x4 <--- x0 (b>0)
x4 <--- x2 (b<0)
x5 <--- x0 (b>0)
DAG[2]: 3.9%
x1 <--- x0 (b>0)
x1 <--- x2 (b>0)
x2 <--- x3 (b>0)
x3 <--- x0 (b>0)
x4 <--- x0 (b>0)
x4 <--- x2 (b<0)
x5 <--- x0 (b>0)
Probability
Using the get_probabilities() method, we can get the probability of
bootstrapping.
prob = result.get_probabilities(min_causal_effect=0.01)
print(prob)
[[0. 0.178 0.163 0.482 0.134 0.246]
[0.773 0. 0.775 0.202 0.069 0.064]
[0.2 0.225 0. 0.761 0.093 0.032]
[0.183 0.166 0.19 0. 0.031 0.084]
[0.866 0.074 0.88 0.121 0. 0.043]
[0.754 0.059 0.065 0.095 0.062 0. ]]
Total Causal Effects
Using the get_total_causal_effects() method, we can get the list of
total causal effect. The total causal effects we can get are dictionary
type variable. We can display the list nicely by assigning it to
pandas.DataFrame. Also, we have replaced the variable index with a label
below.
causal_effects = result.get_total_causal_effects(min_causal_effect=0.01)
# Assign to pandas.DataFrame for pretty display
df = pd.DataFrame(causal_effects)
labels = [f'x{i}' for i in range(X.shape[1])]
df['from'] = df['from'].apply(lambda x : labels[x])
df['to'] = df['to'].apply(lambda x : labels[x])
df
| from | to | effect | probability | |
|---|---|---|---|---|
| 0 | x2 | x4 | -0.986006 | 0.884 |
| 1 | x0 | x4 | 7.975821 | 0.866 |
| 2 | x3 | x4 | 17.169757 | 0.858 |
| 3 | x3 | x1 | 20.553538 | 0.794 |
| 4 | x0 | x1 | 3.020369 | 0.793 |
| 5 | x3 | x2 | 5.968590 | 0.788 |
| 6 | x2 | x1 | 1.992771 | 0.775 |
| 7 | x0 | x5 | 3.984278 | 0.754 |
| 8 | x3 | x5 | 11.686617 | 0.657 |
| 9 | x3 | x0 | 2.920996 | 0.653 |
| 10 | x0 | x2 | 1.679845 | 0.343 |
| 11 | x2 | x5 | 0.155444 | 0.282 |
| 12 | x5 | x4 | 1.550997 | 0.266 |
| 13 | x0 | x3 | 0.305366 | 0.260 |
| 14 | x5 | x1 | 0.939446 | 0.259 |
| 15 | x5 | x0 | 0.249365 | 0.246 |
| 16 | x1 | x4 | 0.863039 | 0.245 |
| 17 | x2 | x0 | 0.120842 | 0.244 |
| 18 | x1 | x2 | 0.285349 | 0.225 |
| 19 | x1 | x5 | 0.576121 | 0.199 |
| 20 | x1 | x0 | 0.144407 | 0.197 |
| 21 | x5 | x2 | 0.451434 | 0.196 |
| 22 | x1 | x3 | 0.046961 | 0.194 |
| 23 | x2 | x3 | 0.133917 | 0.191 |
| 24 | x5 | x3 | 0.076654 | 0.168 |
| 25 | x4 | x1 | 0.362045 | 0.144 |
| 26 | x4 | x5 | 0.478376 | 0.143 |
| 27 | x4 | x0 | 0.123534 | 0.134 |
| 28 | x4 | x2 | -0.139721 | 0.097 |
| 29 | x4 | x3 | -0.006454 | 0.043 |
We can easily perform sorting operations with pandas.DataFrame.
df.sort_values('effect', ascending=False).head()
| from | to | effect | probability | |
|---|---|---|---|---|
| 3 | x3 | x1 | 20.553538 | 0.794 |
| 2 | x3 | x4 | 17.169757 | 0.858 |
| 8 | x3 | x5 | 11.686617 | 0.657 |
| 1 | x0 | x4 | 7.975821 | 0.866 |
| 5 | x3 | x2 | 5.968590 | 0.788 |
df.sort_values('probability', ascending=True).head()
| from | to | effect | probability | |
|---|---|---|---|---|
| 29 | x4 | x3 | -0.006454 | 0.043 |
| 28 | x4 | x2 | -0.139721 | 0.097 |
| 27 | x4 | x0 | 0.123534 | 0.134 |
| 26 | x4 | x5 | 0.478376 | 0.143 |
| 25 | x4 | x1 | 0.362045 | 0.144 |
And with pandas.DataFrame, we can easily filter by keywords. The following code extracts the causal direction towards x1.
df[df['to']=='x1'].head()
| from | to | effect | probability | |
|---|---|---|---|---|
| 3 | x3 | x1 | 20.553538 | 0.794 |
| 4 | x0 | x1 | 3.020369 | 0.793 |
| 6 | x2 | x1 | 1.992771 | 0.775 |
| 14 | x5 | x1 | 0.939446 | 0.259 |
| 25 | x4 | x1 | 0.362045 | 0.144 |
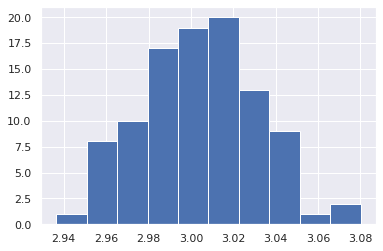
Because it holds the raw data of the total causal effect (the original data for calculating the median), it is possible to draw a histogram of the values of the causal effect, as shown below.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
%matplotlib inline
from_index = 3 # index of x3
to_index = 0 # index of x0
plt.hist(result.total_effects_[:, to_index, from_index])
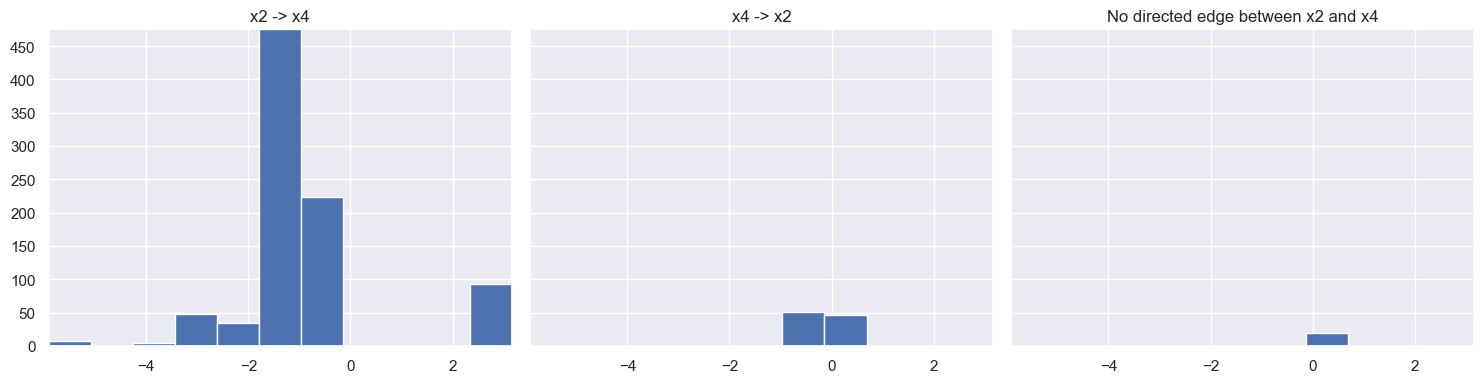
Furthermore, when we separate the bootstrap coefficient distributions into the three structural cases - X->Y, Y->X, and no directed edge between X and Y - the resulting histograms are shown below.
import matplotlib.ticker as ticker
from_index, to_index = 2, 4
te_xy = result.total_effects_[:, to_index, from_index]
te_yx = result.total_effects_[:, from_index, to_index]
both_zero_mask = (te_xy == 0.0) & (te_yx == 0.0)
te_zero = result.total_effects_[both_zero_mask, to_index, from_index]
te_xy = te_xy[te_xy != 0.0]
te_yx = te_yx[te_yx != 0.0]
bins_count = int(np.ceil(1 + np.log2(max(n_samples, 1))))
# calculate xmin, xmax
arr_list = [te_xy, te_yx, te_zero]
if any(a.size > 0 for a in arr_list):
vals = np.concatenate([a for a in arr_list if a.size > 0])
else:
vals = np.array([0.0])
xmin, xmax = np.min(vals), np.max(vals)
if xmin == xmax:
eps = 1e-9 if xmin == 0 else abs(xmin) * 1e-3
xmin, xmax = xmin - eps, xmax + eps
bin_edges = np.linspace(xmin, xmax, bins_count + 1)
# calculate ymax
counts_xy, _ = np.histogram(te_xy, bins=bin_edges) if te_xy.size > 0 else (np.zeros(bins_count, dtype=int), None)
counts_yx, _ = np.histogram(te_yx, bins=bin_edges) if te_yx.size > 0 else (np.zeros(bins_count, dtype=int), None)
counts_zz, _ = np.histogram(te_zero, bins=bin_edges) if te_zero.size > 0 else (np.zeros(bins_count, dtype=int), None)
ymax = int(max(counts_xy.max(initial=0), counts_yx.max(initial=0), counts_zz.max(initial=0)))
ymax = max(ymax, 1)
# If you want to set ymax to the number of bootstrap iterations, uncomment next line.
# ymax = n_samples
# display histograms
fig, axes = plt.subplots(1, 3, figsize=(15, 4), sharex=True, sharey=True)
labels = [f'x{i}' for i in range(X.shape[1])]
axes[0].hist(te_xy, bins=bin_edges)
axes[0].set_title(f"{labels[from_index]} -> {labels[to_index]}")
axes[0].yaxis.set_major_locator(ticker.MaxNLocator(integer=True))
axes[0].set_xlim(xmin, xmax)
axes[0].set_ylim(0, ymax)
axes[1].hist(te_yx, bins=bin_edges)
axes[1].set_title(f"{labels[to_index]} -> {labels[from_index]}")
axes[1].yaxis.set_major_locator(ticker.MaxNLocator(integer=True))
axes[1].set_xlim(xmin, xmax)
axes[1].set_ylim(0, ymax)
axes[2].hist(te_zero, bins=bin_edges)
axes[2].set_title("No directed edge between " + labels[from_index] + " and " + labels[to_index])
axes[2].yaxis.set_major_locator(ticker.MaxNLocator(integer=True))
axes[2].set_xlim(xmin, xmax)
axes[2].set_ylim(0, ymax)
plt.tight_layout()
plt.show()
Bootstrap Probability of Path
Using the get_paths() method, we can explore all paths from any
variable to any variable and calculate the bootstrap probability for
each path. The path will be output as an array of variable indices. For
example, the array [3, 0, 1] shows the path from variable X3 through
variable X0 to variable X1.
from_index = 3 # index of x3
to_index = 1 # index of x1
pd.DataFrame(result.get_paths(from_index, to_index))
| path | effect | probability | |
|---|---|---|---|
| 0 | [3, 2, 1] | 11.914854 | 0.660 |
| 1 | [3, 0, 1] | 8.756234 | 0.443 |
| 2 | [3, 1] | 2.105700 | 0.202 |
| 3 | [3, 2, 0, 1] | 1.635862 | 0.094 |
| 4 | [3, 5, 0, 1] | 8.670284 | 0.060 |
| 5 | [3, 4, 0, 1] | 6.979752 | 0.054 |
| 6 | [3, 2, 4, 1] | -1.146483 | 0.038 |
| 7 | [3, 0, 4, 1] | 4.459602 | 0.028 |
| 8 | [3, 0, 5, 1] | 2.864025 | 0.026 |
| 9 | [3, 2, 4, 0, 1] | -4.602396 | 0.024 |
| 10 | [3, 0, 2, 1] | -1.512156 | 0.022 |
| 11 | [3, 4, 1] | 4.954881 | 0.019 |
| 12 | [3, 2, 5, 0, 1] | 0.374461 | 0.009 |
| 13 | [3, 2, 0, 5, 1] | 0.583856 | 0.008 |
| 14 | [3, 5, 4, 0, 1] | 6.941594 | 0.007 |
| 15 | [3, 4, 5, 0, 1] | 2.145360 | 0.007 |
| 16 | [3, 4, 2, 1] | -1.080988 | 0.007 |
| 17 | [3, 5, 1] | 3.272935 | 0.006 |
| 18 | [3, 4, 0, 5, 1] | 2.697207 | 0.005 |
| 19 | [3, 4, 2, 0, 1] | -0.219167 | 0.005 |
| 20 | [3, 0, 5, 2, 1] | 5.181321 | 0.004 |
| 21 | [3, 5, 0, 4, 1] | 5.442240 | 0.004 |
| 22 | [3, 5, 2, 1] | 1.537410 | 0.003 |
| 23 | [3, 4, 5, 1] | 4.166390 | 0.003 |
| 24 | [3, 0, 5, 4, 1] | -0.522766 | 0.003 |
| 25 | [3, 2, 4, 5, 0, 1] | -1.083415 | 0.003 |
| 26 | [3, 5, 4, 1] | -7.351469 | 0.002 |
| 27 | [3, 2, 4, 5, 1] | 0.203801 | 0.002 |
| 28 | [3, 2, 4, 0, 5, 1] | -1.303056 | 0.002 |
| 29 | [3, 5, 2, 0, 1] | -0.006054 | 0.002 |
| 30 | [3, 5, 4, 2, 1] | -15.137090 | 0.002 |
| 31 | [3, 4, 0, 2, 1] | -3.885974 | 0.001 |
| 32 | [3, 2, 5, 4, 1] | -0.035426 | 0.001 |
| 33 | [3, 5, 0, 2, 1] | 7.112032 | 0.001 |
| 34 | [3, 2, 0, 4, 1] | -3.206907 | 0.001 |
| 35 | [3, 5, 2, 4, 0, 1] | 0.351331 | 0.001 |
| 36 | [3, 0, 4, 5, 1] | -0.695107 | 0.001 |
| 37 | [3, 5, 4, 0, 2, 1] | 14.386599 | 0.001 |
| 38 | [3, 4, 2, 0, 5, 1] | -0.072976 | 0.001 |